Oct 9, 2025
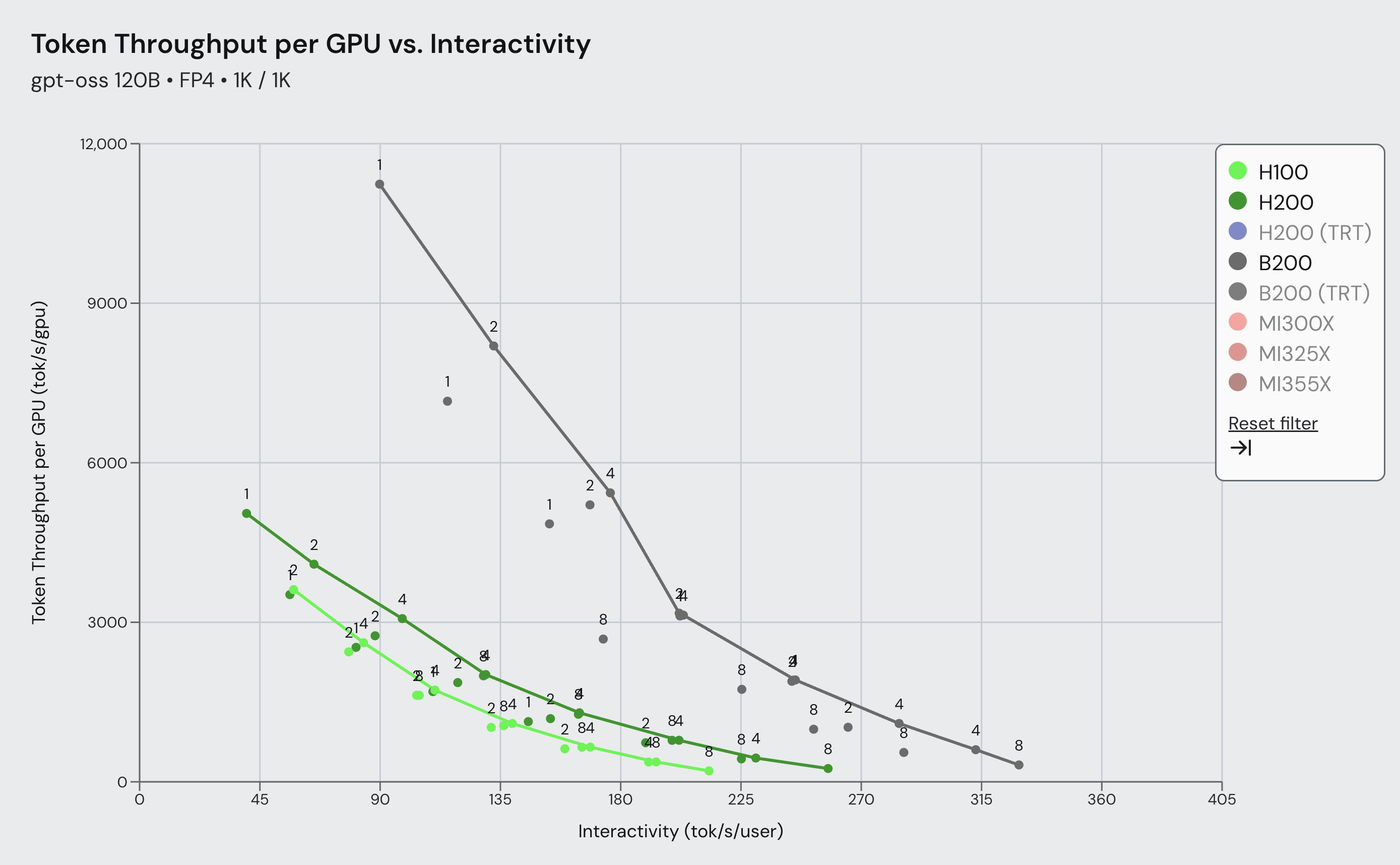
SemiAnalysis InferenceMAX: vLLM and NVIDIA Accelerate Blackwell Inference
Sep 29, 2025
DeepSeek-V3.2-Exp in vLLM: Fine-Grained Sparse Attention in Action
Sep 16, 2025
The First vLLM Meetup in Korea
Sep 11, 2025
vLLM Semantic Router: Next Phase in LLM inference
Sep 11, 2025
vLLM Now Supports Qwen3-Next: Hybrid Architecture with Extreme Efficiency
Sep 5, 2025
Serving Geospatial, Vision, and Beyond: Enabling Multimodal Output Processing in vLLM
Sep 5, 2025
Inside vLLM: Anatomy of a High-Throughput LLM Inference System
Aug 20, 2025
Introduction to torch.compile and How It Works with vLLM
Aug 19, 2025
GLM-4.5 Meets vLLM: Built for Intelligent Agents
Aug 11, 2025
CUDA Core Dump: An Effective Tool to Debug Memory Access Issues and Beyond
Aug 5, 2025
vLLM Now Supports gpt-oss
Jun 30, 2025
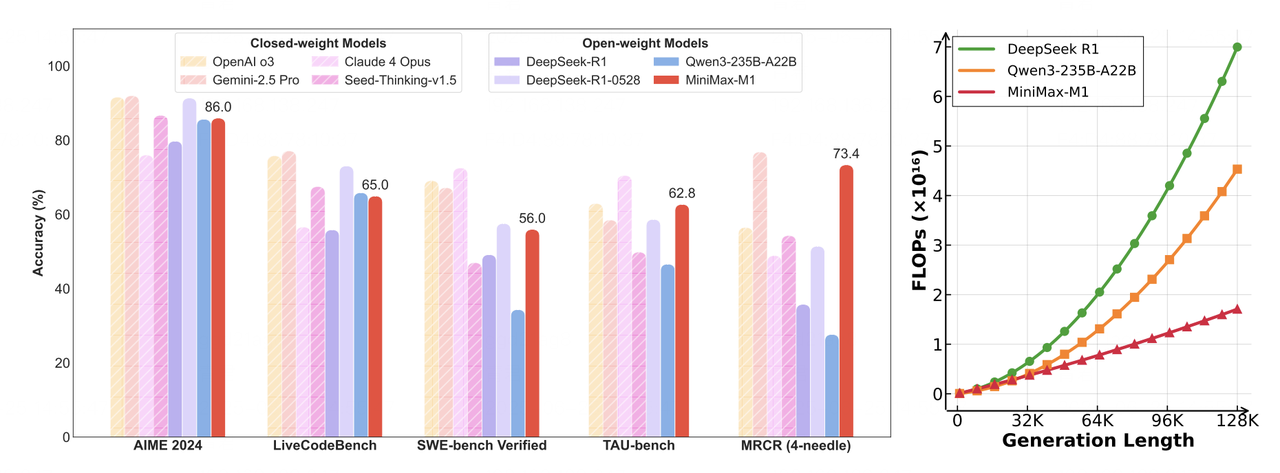
MiniMax-M1 Hybrid Architecture Meets vLLM: Long Context, Fast Inference
May 12, 2025
Introducing vLLM Hardware Plugin, Best Practice from Ascend NPU
Apr 23, 2025
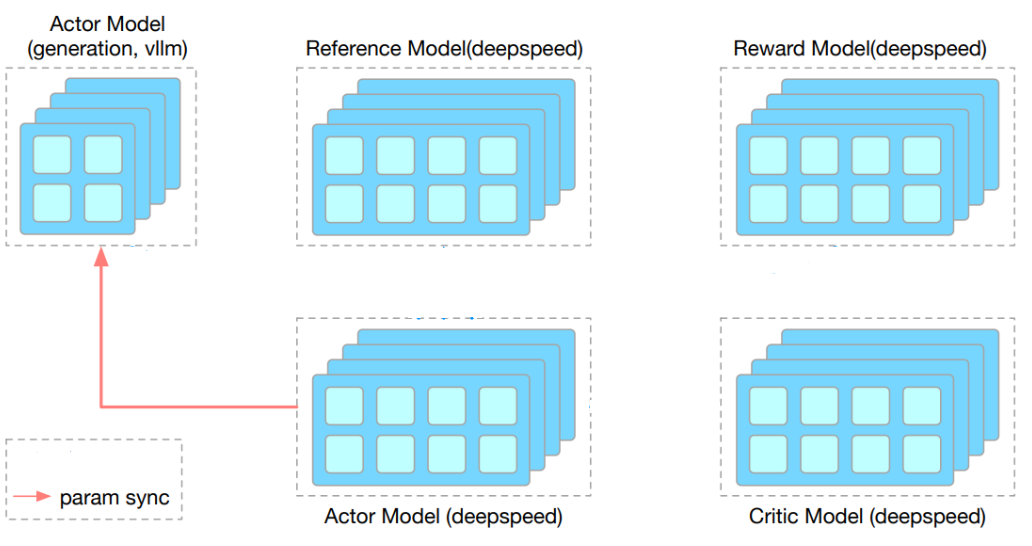
Accelerating RLHF with vLLM, Best Practice from OpenRLHF
Apr 11, 2025
Transformers backend integration in vLLM
Apr 5, 2025
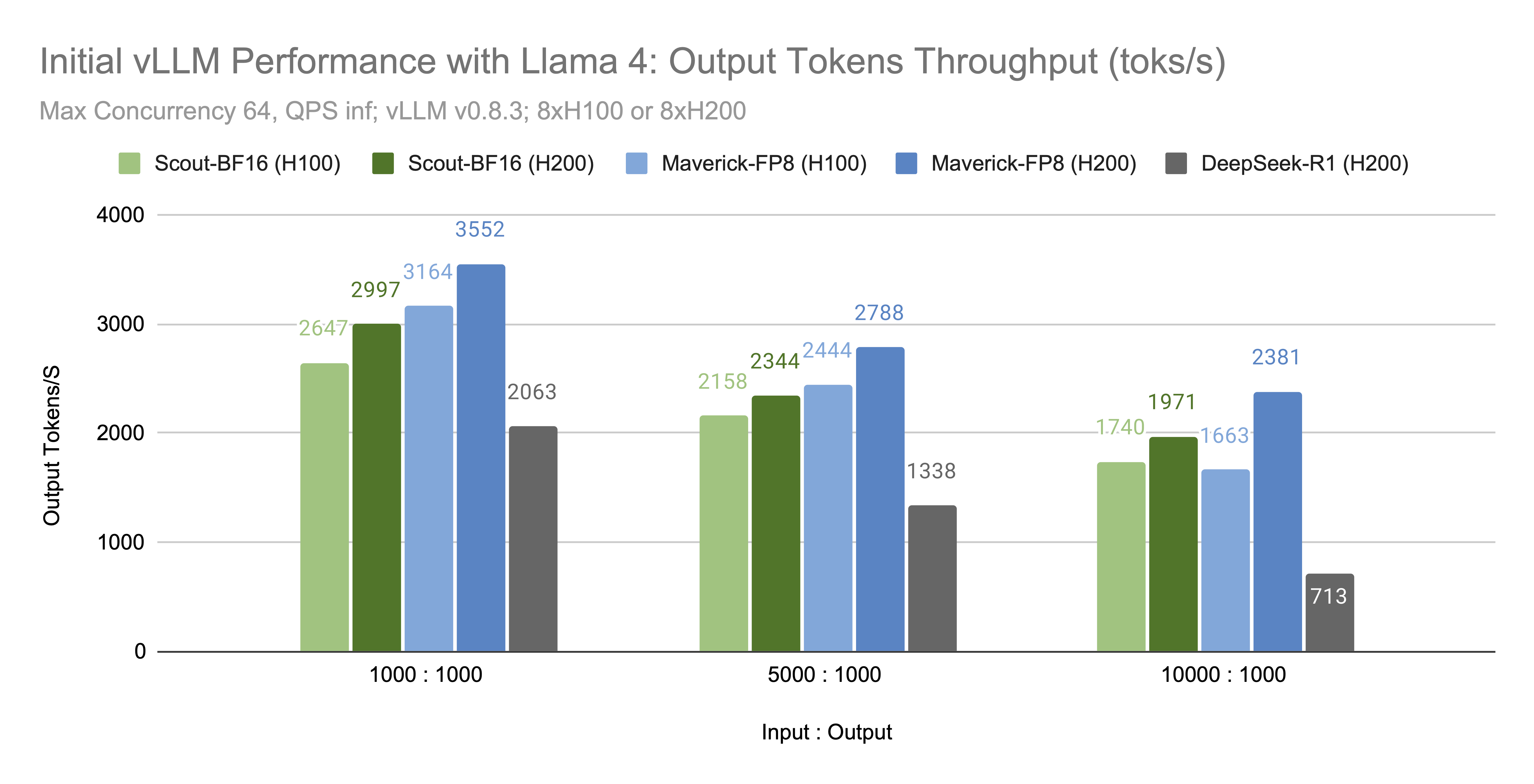
Llama 4 in vLLM
Feb 24, 2025
PTPC-FP8: Boosting vLLM Performance on AMD ROCm
Feb 21, 2025
Introducing AIBrix: A Scalable, Cost-Effective Control Plane for vLLM
Feb 17, 2025
Distributed Inference with vLLM
Jan 27, 2025
vLLM V1: A Major Upgrade to vLLM's Core Architecture
Jan 27, 2025
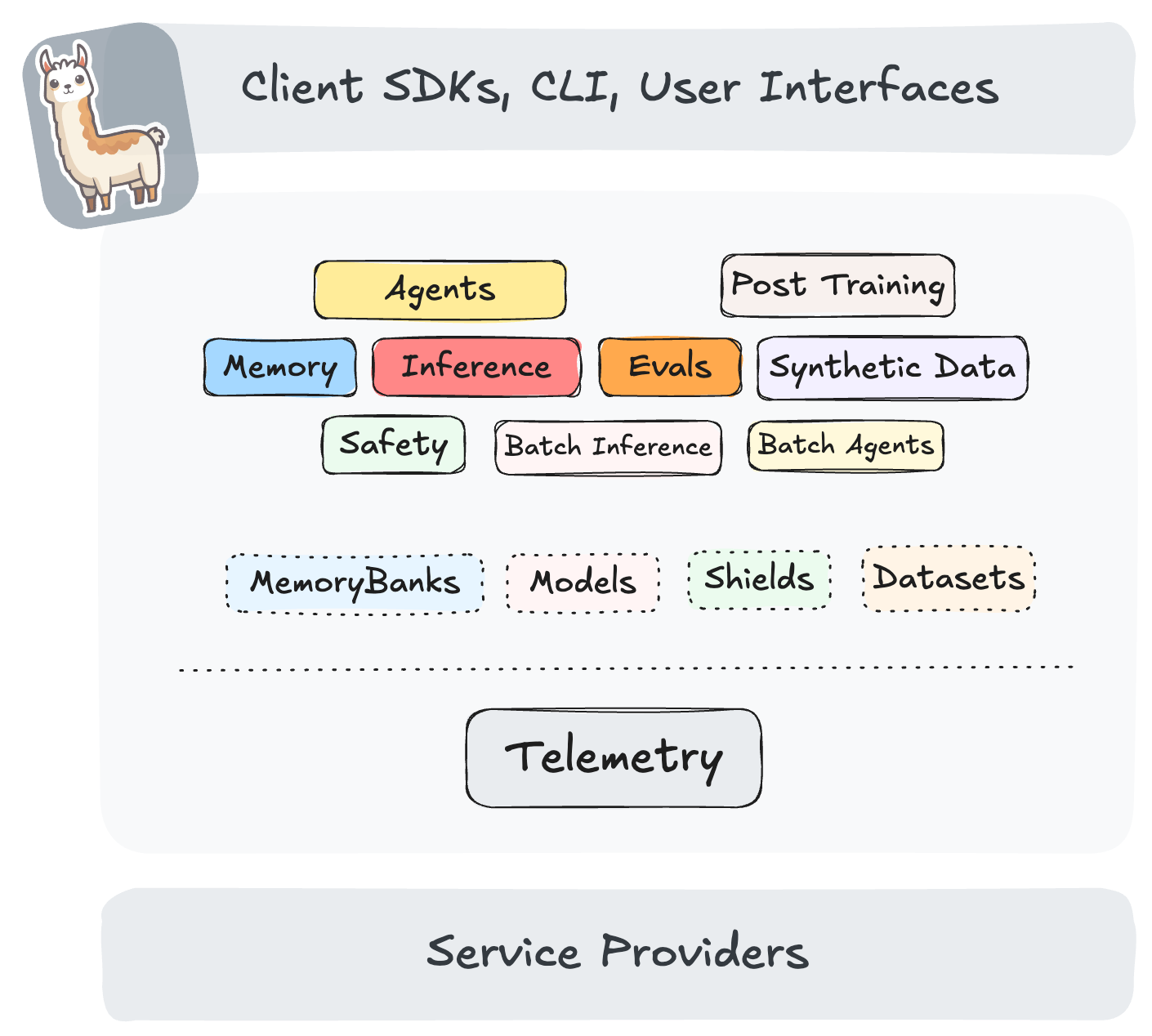
Introducing vLLM Inference Provider in Llama Stack
Jan 21, 2025
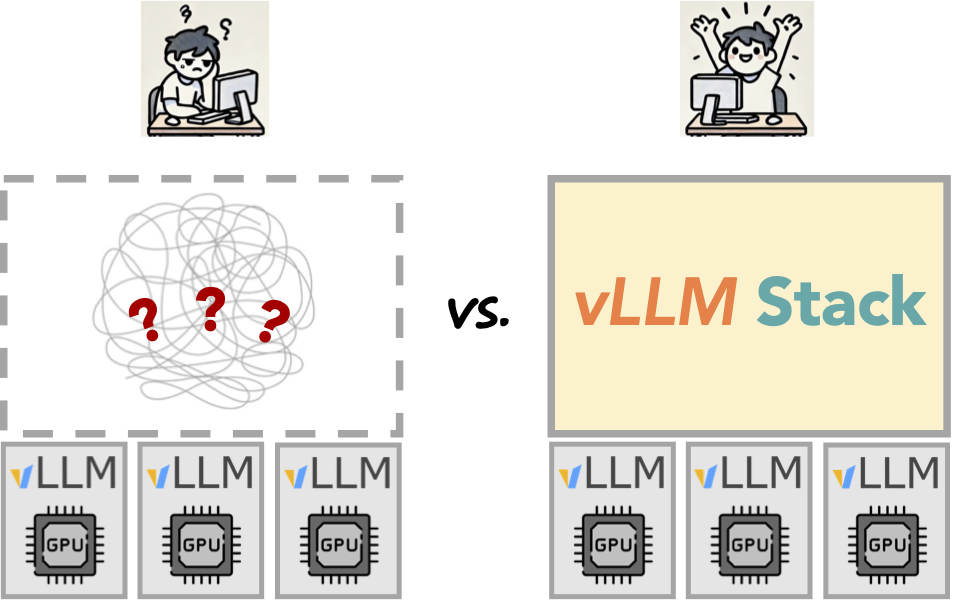
High Performance and Easy Deployment of vLLM in K8S with vLLM production-stack
Jan 14, 2025
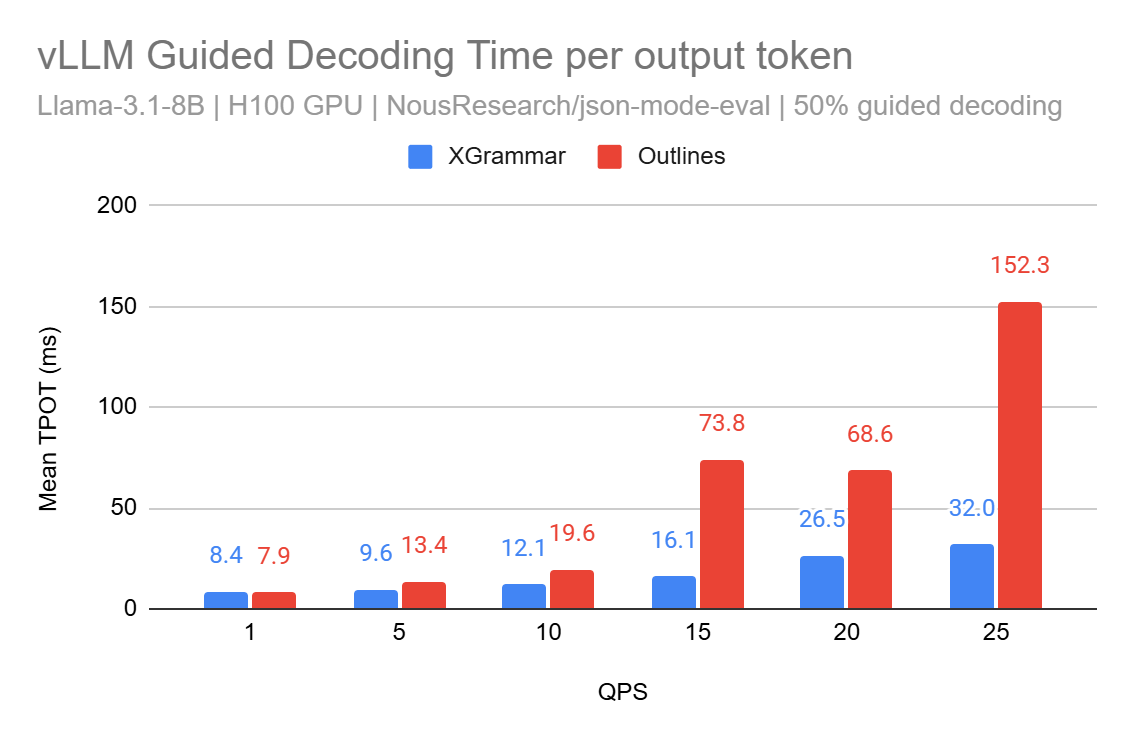
Structured Decoding in vLLM: a gentle introduction
Jan 10, 2025
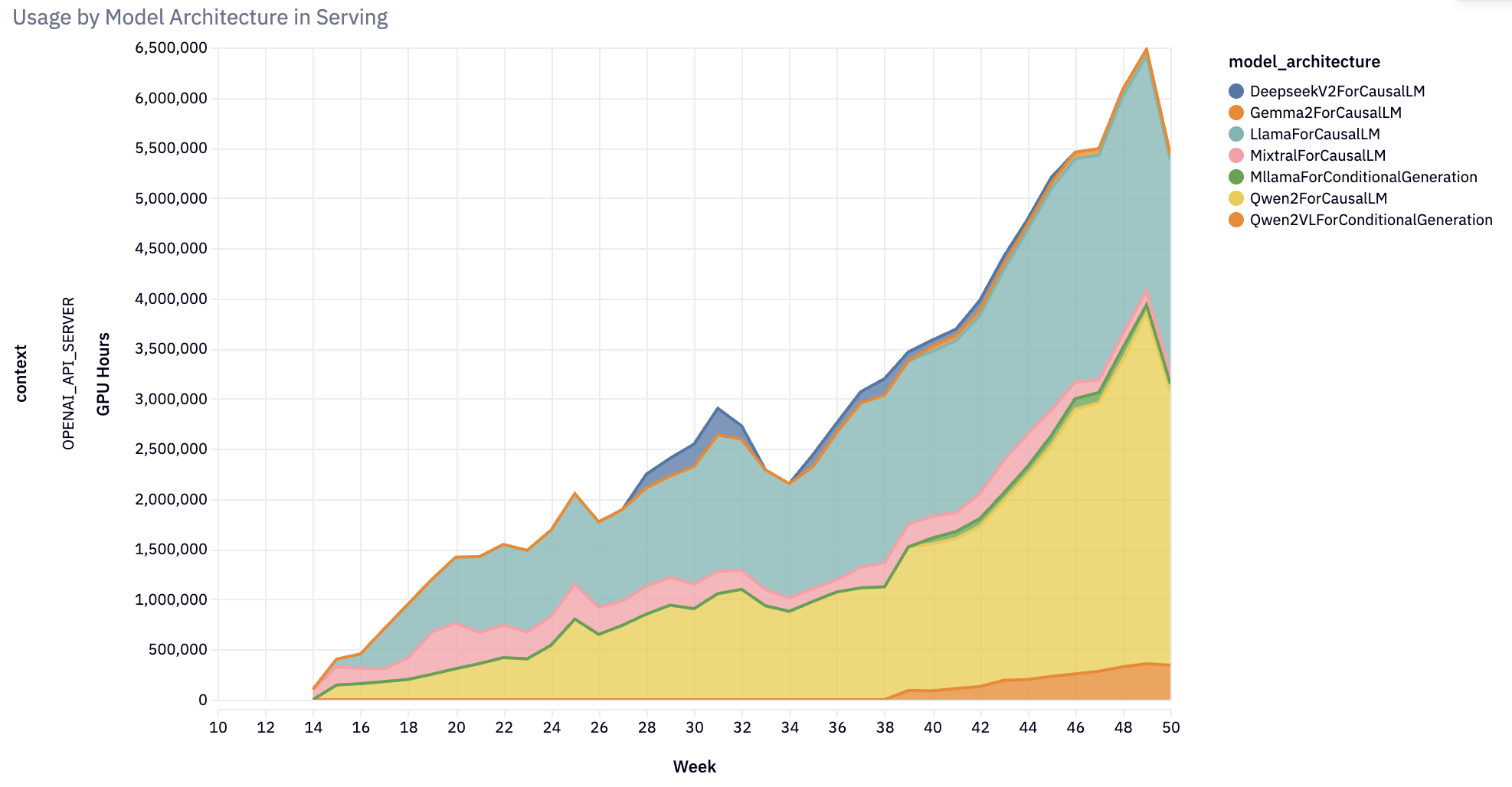
vLLM 2024 Retrospective and 2025 Vision
Jan 10, 2025
Installing and Developing vLLM with Ease
Oct 23, 2024
Serving LLMs on AMD MI300X: Best Practices
Oct 17, 2024
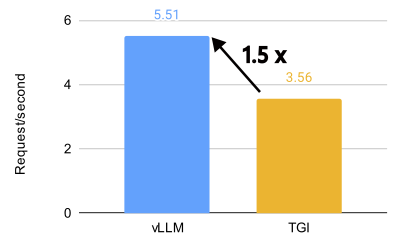
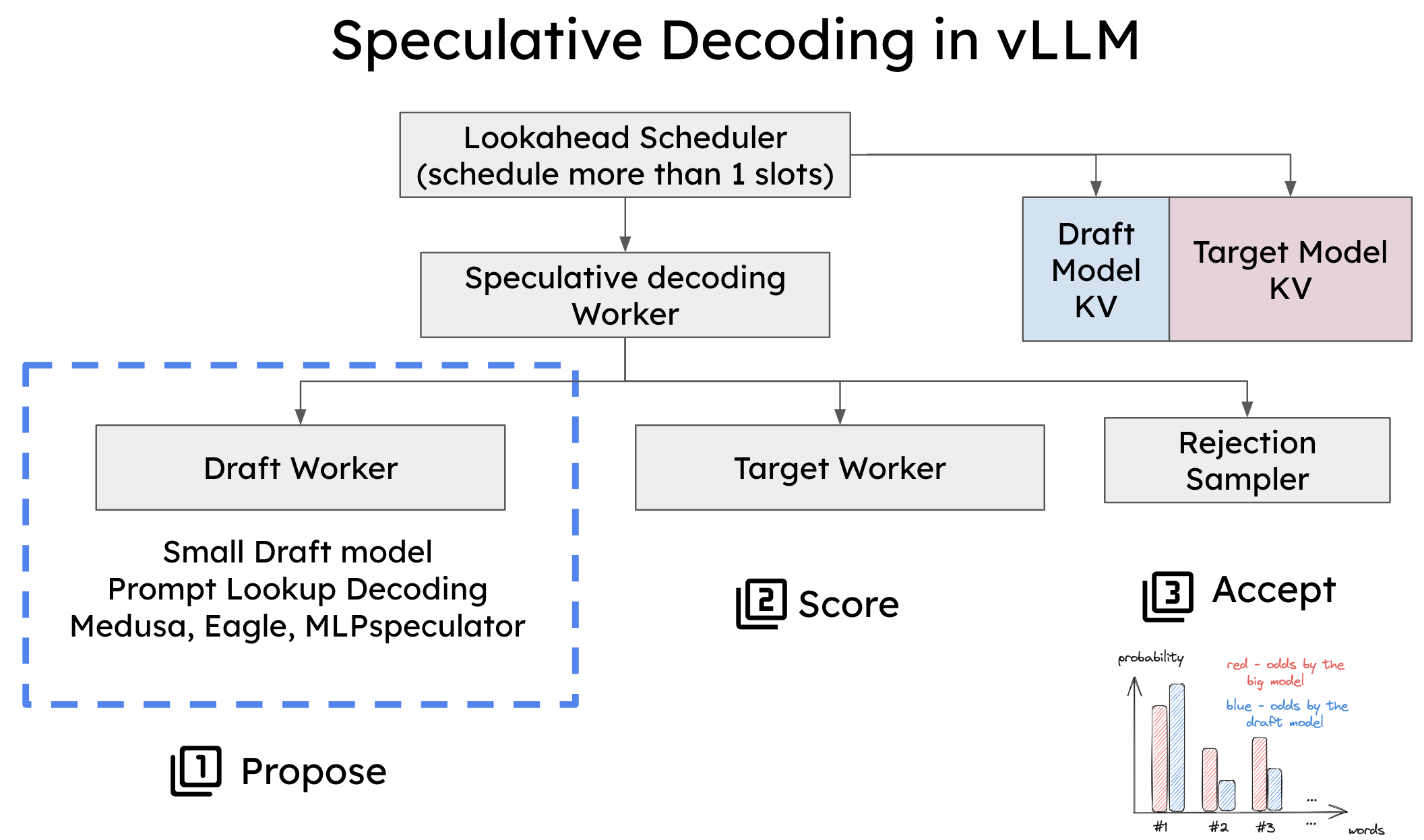
How Speculative Decoding Boosts vLLM Performance by up to 2.8x
Sep 5, 2024
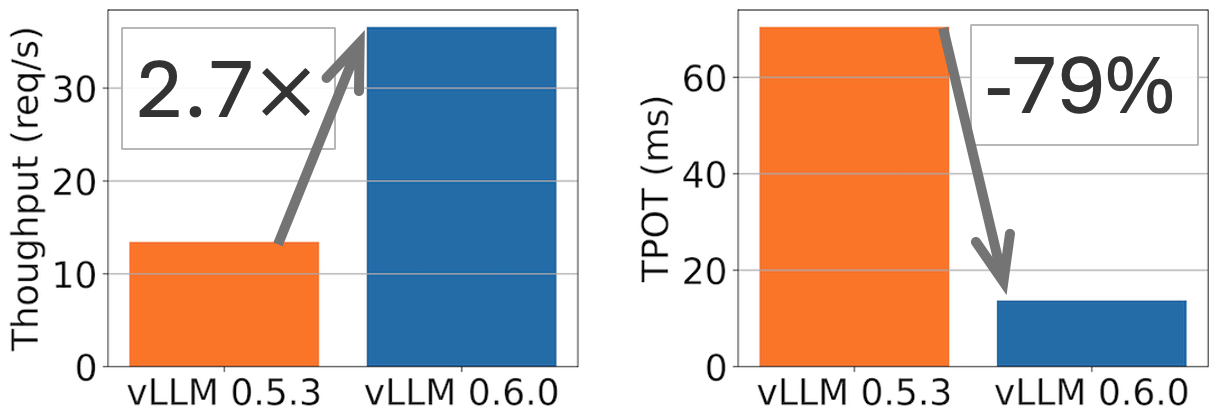
vLLM v0.6.0: 2.7x Throughput Improvement and 5x Latency Reduction
Jul 25, 2024
vLLM’s Open Governance and Performance Roadmap
Jul 23, 2024
Announcing Llama 3.1 Support in vLLM
Nov 14, 2023
Notes on vLLM v.s. DeepSpeed-FastGen
Jun 20, 2023
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention